SQL Server Denali 新增的資料行存放區索引(下)
文‧圖/胡百敬 2011/11/14 下午 06:45:32
在上篇專欄中,我們討論了資料行存放區索引的運作原理與建置方式,在本篇終將繼續說明使用資料行存放區索引的注意事項與限制。
SQL Server Denali 版本為資料行存放區索引也新增了一個查詢提示:ignore_nonclustered_columnstore_index,可以此要求雖然目的資料表有建立資料行存放區索引,但依然不准用。你可用來比較執行計畫有無採用資料行存放區索引對執行效能的差異,或是 SQL Server 在特殊狀況下做錯執行計畫,藉此強迫採用你所期待的作法,其範例如下:
create index idx3 on BigFactInternetSales(PromotionKey)
select distinct PromotionKey from BigFactInternetSales
select distinct PromotionKey from BigFactInternetSales option(ignore_nonclustered_columnstore_index)
上述範例的執行計畫如圖 1:
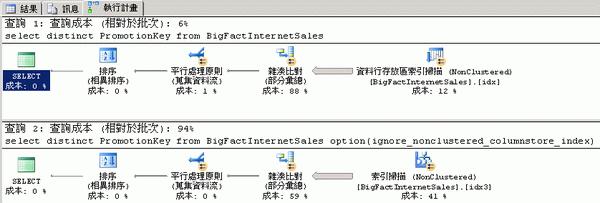
▲ 圖1 以 ignore_nonclustered_columnstore_index 查詢提示強制 SQL Server Denali 不採用資料行存放區索引
相較之下,可以發現資料行存放區索引效能好過一般的索引掃描:
資料表 'BigFactInternetSales'。掃描計數 4,邏輯讀取 108,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'Worktable'。掃描計數 0,邏輯讀取 0,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
SQL Server 執行次數:
,CPU 時間 = 47 ms,經過時間 = 18 ms。
(4 個資料列受到影響)
資料表 'Worktable'。掃描計數 0,邏輯讀取 0,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'BigFactInternetSales'。掃描計數 7,邏輯讀取 37452,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
SQL Server 執行次數:
,CPU 時間 = 5016 ms,經過時間 = 3449 ms。
一旦建立了 資料行存放區索引後,大部分的資料庫日常維運工作,如:透過 SQL Server Management Studio(SSMS)管理、備份/還原、鏡像(Mirroring)、記錄傳送(Log shipping)…等,都不受影響。話雖如此,但 SQL Server Denali 版本提供的資料行存放區索引仍有很多的限制。
限制
當資料欄位類型是以下列表中的一種時,無法將該欄位納入資料行存放區索引:
●decimal > 18 位小數
●Binary
●大型二進位資料(BLOB)
●(n)varchar(max)
●Uniqueidentifier
●Date/time 類型 > 8 位元組
●自訂 CLR 資料類型
在未來的 SQL Server 版本應該會放寬這些限制,然而,由於資料行存放區索引適用在資料倉儲/超市的數值資料表,一般而言,數值資料表也不常用上述的資料類型,所以 Denali 當下的限制或許不會造成太大的困擾。
更新唯讀資料表
凡建立了資料行存放區索引後,該資料表就變成唯讀,無法對其增、刪、修乃至於 bulk 增、刪,這是比較大的困擾,需要在設計資料庫時小心考慮維護資料的作法。一般而言,修改資料可以採用兩種方式:
●停用資料行存放區索引,更新完資料後,再重建索引
1. 先利用以下語法停用:
ALTER INDEX <索引名稱> ON <資料表名稱> DISABLE
2. 更新資料。
3. 而後再重建索引:
ALTER INDEX <索引名稱> ON <資料表名稱> REBUILD
當然,也可以先移除(Drop)資料行存放區索引,更新完資料後,再建立(Create)該索引。若資料量很大,不管是停用還是移除在重建,都將耗費線上系統的資源與時間。
●分割資料,透過 Switch 附加新的記錄到資料表
其步驟約略如下:
1. 建立符合分割的中介資料表,載入資料到中介資料表。
2. 針對中介資料表建立資料行存放區索引,其欄位結構要與目標資料表的資料行存放區索引相同。
CREATE NONCLUSTERED COLUMNSTORE INDEX <索引名稱> ON <中介資料表名稱> (欄位列表)
否則在 switch 分割時,將會有類似如下的錯誤:
訊息 4947,層級 16,狀態 1,行 1
ALTER TABLE SWITCH 陳述式失敗。來源資料表 '…' 中的索引與目標資料表 '…' 中的索引 '<目標資料表所建的資料行存放區索引>' 不是完全相同。
3. 對目標(已建立 資料行存放區索引與分割的資料表)執行 Split,以建立空的分割。
4. Switch 該中介資料表的分割到目標資料表。
ALTER TABLE <中介資料表名稱> SWITCH TO <目標資料表名稱> PARTITION
由於在載入資料和建置資料行存放區索引都是在不同的工作資料表,僅有在最後 Switch 分割到目標資料表,這只是修改中繼資料,瞬間可以完成,整個遞增載入資料的過程較不影響線上的系統。
批次運算
資料行存放區索引適用於 Inner Join、Star Join、掃描(scan)與彙總大量資料,當查詢採用Outer join、Union 時,仍可以使用資料行存放區索引,但無法透過批次運算提升效能。範例如下:
select p.EnglishPromotionName,count(f.OrderDate)
from DimPromotion p left join BigFactInternetSales f
on p.PromotionKey=f.PromotionKey
group by p.EnglishPromotionName
order by p.EnglishPromotionName;
上述查詢由於透過 Left Outer Join,故「資料行存放區索引掃描」運算子的「估計的執行模式」採用「Row」,也就是逐筆運算,如圖 2 所示:
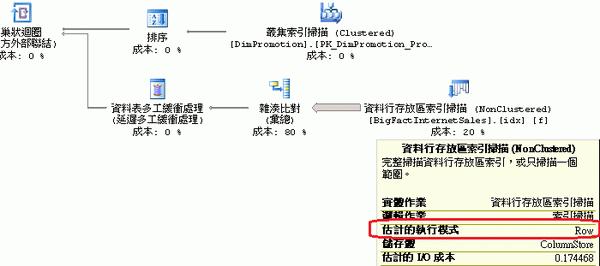
▲ 圖 2:以單筆記錄的方式掃描資料行存放區索引
而上述的邏輯可以改成先透過資料行存放區索引算出有 PromotionKey 的 count 彙總後,再與 DimPromotion 資料表做 left outer join,避免對擁有大量資料的資料行存放區索引先做 left outer join,範例語法如下:
with EqJoin(PromotionKey,CourntSales) as
(
select PromotionKey, count(*) CourntSales
from BigFactInternetSales
group by PromotionKey
)
select p.EnglishPromotionName,IsNull(CourntSales,0)
from DimPromotion p left join EqJoin e
on p.PromotionKey=e.PromotionKey
order by 1
則整個執行計畫變成圖 3:

▲ 圖 3:以批次的方式掃描資料行存放區索引。
這時,「資料行存放區索引掃描」運算子的「估計的執行模式」採用「Batch」,也就是批次運算。兩者的執行結果雖然相同,但所耗的 CPU 運算差異極大,其執行後的統計資訊如下:
資料表 'Worktable'。掃描計數 1,邏輯讀取 39,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'BigFactInternetSales'。掃描計數 1,邏輯讀取 617,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'DimPromotion'。掃描計數 1,邏輯讀取 3,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
SQL Server 執行次數:
,CPU 時間 = 5578 ms,經過時間 = 5578 ms。
(16 個資料列受到影響)
資料表 'BigFactInternetSales'。掃描計數 4,邏輯讀取 112,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'DimPromotion'。掃描計數 1,邏輯讀取 3,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'Worktable'。掃描計數 0,邏輯讀取 0,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
資料表 'Worktable'。掃描計數 0,邏輯讀取 0,實體讀取 0,讀取前讀取 0,LOB 邏輯讀取 0,LOB 實體讀取 0,LOB 讀取前讀取 0。
SQL Server 執行次數:
,CPU 時間 = 16 ms,經過時間 = 24 ms。
從上述的統計資料可以看到批次運作較逐筆運作提升了近 200 倍的效能。無法對 Outer Join、Union 等語法執行批次運算是 SQL Server Denali 版本的限制,期待在未來的版本中,SQL Server 可以有更佳的執行計畫,以放寬前述的限制。
總結而言,資料行存放區索引適合建立在大部分僅查詢用途的資料表,更新資料的方式為批次附加新記錄,資料表允許維護的時間(例如夜晚的批次作業),以執行分割移轉或停用/重建索引。
若僅是在大資料表內搜尋少量資料,則以往的 B-tree 結構索引更為適合(傳統的 Index Seek)。換句話說,資料行存放區索引是 DBA 用來提升效能的選項之一,但無法當作可解決所有問題的終極機制。由於資料行存放區索引可以在現行的軟/硬體上施行,毋須特殊的架構與技術,若你有近似的資料結構與應用需求,這將是個超值的解法。
